Project Description:
Domain-specific accelerators (DSAs) have shown to offer significant performance and energy efficiency over general-purpose CPUs to meet the ever-increasing performance needs. However, it is well-known that the DSAs in field-programmable gate-arrays (FPGAs) or application specific integrated circuits (ASICs) are hard to design and require deep hardware knowledge to achieve high performance. Although the recent advances in high-level synthesis (HLS) tools made it possible to compile behavioral-level C/C++ programs to FPGA or ASIC designs, one still needs to have extensive experience in microarchitecture optimizations using code transformation and pragmas to the input program. The proposed project addresses these problems by developing a fully automated framework for evaluating and optimizing the microarchitecture of a DSA design without the invocation of the time-consuming HLS tools. The goal of this project is to enable a typical software programmer to be able to design highly efficient hardware DSAs, with the quality comparable to those designed by experienced circuit designers.
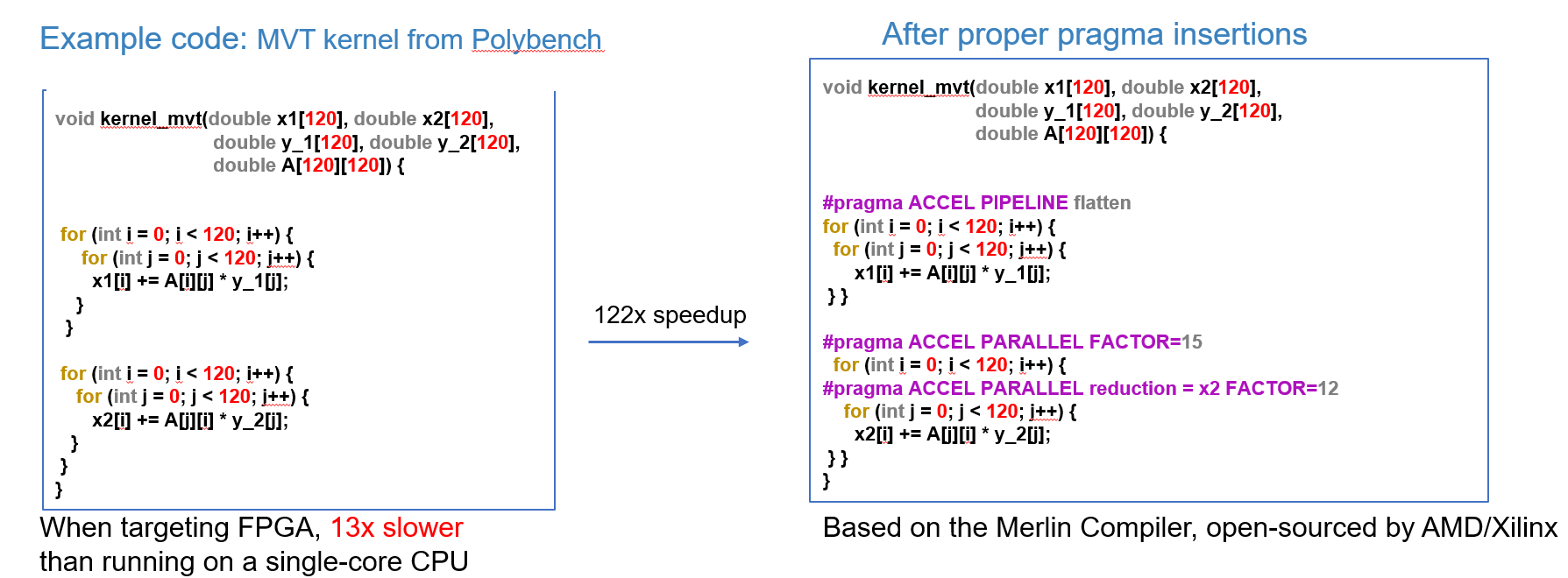
Topic 1: Modeling
a. Robust GNN-based Representation Learning for HLS (ICCAD'23)
https://ieeexplore.ieee.org/document/10323853
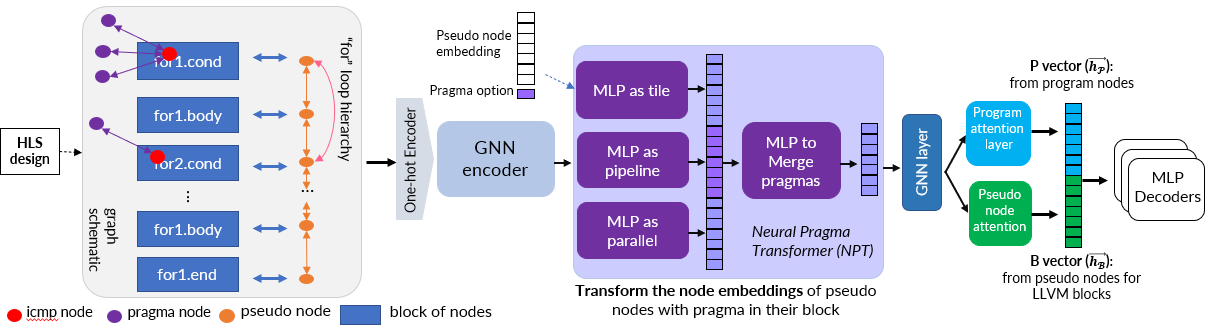
In this paper, we present HARP with a novel hierarchical graph representation of the HLS design. Additionally, HARP decouples the representation of the program and its transformations and includes a neural pragma transformer (NPT) approach to facilitate a more systematic treatment of this process. With the proposed model architecture and graph representation, the prediction performance improved by 29% and the DSE performance improved by 1.15X.
b. Cross-Modality Program Representation Learning for Electronic Design Automation with High-Level Synthesis (MLCAD'24)
https://dl.acm.org/doi/10.1145/3670474.3685952

We propose ProgSG, a model that allows interaction between the source code sequence modality and the graph modality in a deep and fine-grained way. A pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results show that design performance predictions are improved by up to 22%, and identifies designs with an average of 1.10× and 1.26× performance improvement in design space exploration (DSE) task compared to HARP and AutoDSE, respectively.
Topic 2: Generalizability
a. Efficient Task Transfer for HLS DSE (ICCAD'24)
https://arxiv.org/abs/2408.13270
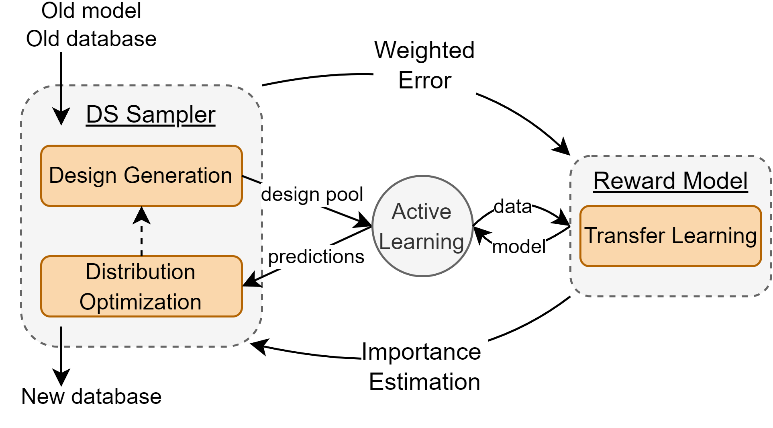
We introduce Active-CEM, a task transfer learning scheme that leverages a model-based explorer with active learning. We further incorporate a toolchain-invariant modeling. Experiment results transitioning to new toolchain show an average performance improvement of 1.58× compared to AutoDSE and a 1.2× improvement over HARP, and reducing the runtime by 2.7×.
b. Hierarchical Mixture of Experts: Generalizable Learning for High-Level Synthesis (AAAI'25)
https://arxiv.org/abs/2410.19225
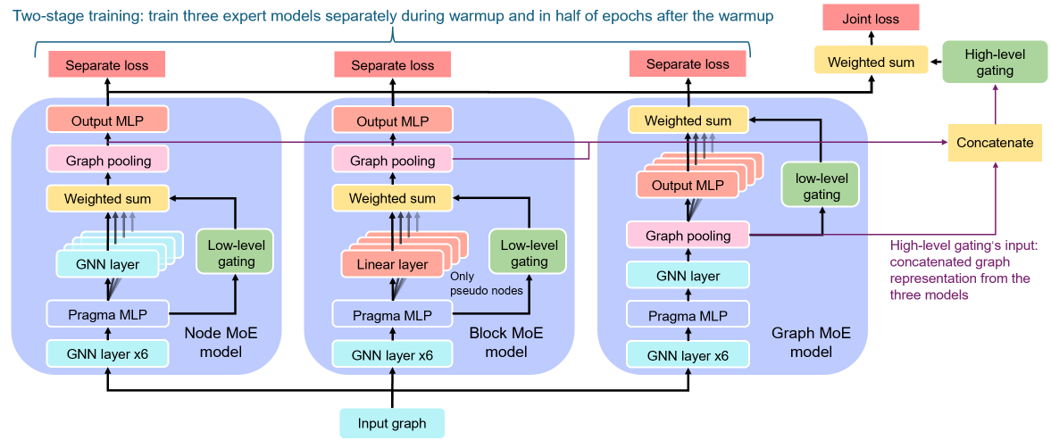
We propose a more domain-generalizable model structure: a two-level hierarchical Mixture of Experts (MoE), that can be flexibly adapted to any GNN model. In the low-level MoE, we apply MoE on three natural granularities of a program: node, basic block, and graph. The high-level MoE learns to aggregate the three granularities for the final decision. We further propose a two-stage training method. Extensive experiments verify the effectiveness of the hierarchical MoE.
Topic 3: Benchmarking
a. Towards a Comprehensive Benchmark for High-Level Synthesis Targeted to FPGAs (NIPS'23 Dataset & Benchmark Track)
https://neurips.cc/virtual/2023/poster/73635
Existing open-source datasets for training HLS models are limited in terms of design complexity and available optimizations. In this paper, we present HLSyn, the first benchmark that addresses these limitations. It contains more complex programs with a wider range of optimization pragmas, making it a comprehensive dataset for training and evaluating design quality prediction models. The HLSyn benchmark consists of 42 unique programs/kernels, resulting in over 42,000 labeled designs. We conduct an extensive comparison of state-of-the-art baselines to assess their effectiveness in predicting design quality.
b. ML Contest for Chip Design with HLS on Kaggle
https://www.kaggle.com/competitions/machine-learning-contest-for-high-le...
We held the first ML contest for chip design on Kaggle using the HLSyn dataset.
Related Events
a. NSF Workshop on AI for Electronic Design Automation (2024)
https://ai4eda-workshop.github.io/
We held the AI4EDA workshop at Vancouver.