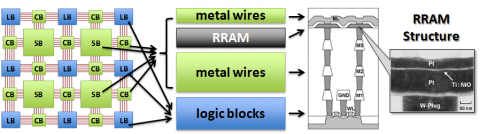
In this paper we introduce a novel FPGA architecture with RRAM-based programmable interconnects (FPGA-RPI). Programmable interconnects are the dominant part of FPGA. We use RRAMs to build programmable interconnects, and we optimize their structures by exploiting opportunities that emerge in RRAM-based circuits. FPGARPI can be fabricated by the existing CMOS-compatible RRAM process. Using an advanced P&R tool named VPR-RPI which was developed to deal with the novel architecture, a customized CAD flow is provided for FPGA-RPI. We apply this flow to the 20 largest MCNC benchmark circuits. Results show that the programmable interconnects of FPGA-RR have a 96% smaller footprint, 55% higher performance, and 79% lower power consumptions compared to other FPGA counterparts.

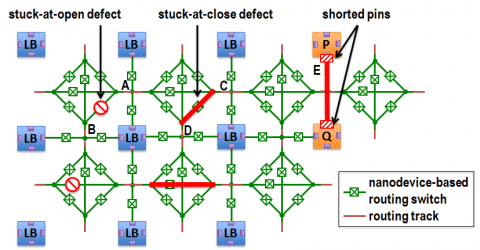
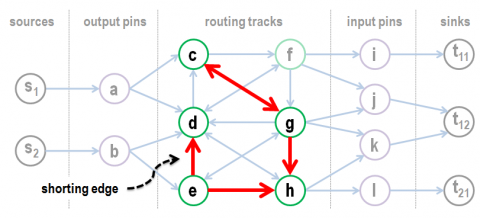
This work focuses on defect tolerance for nanodevice-based programmable interconnects of FPGAs. First, we show that the stuck-closed defects of nanodevices have a much higher impact than the stuck-open defects. Instead of simply avoiding the stuck-closed defects, we use them by treating them as shorting constraints in the routing. We develop a scalable algorithm to perform timing-driven routing under these extra constraints. We also enhance the placement algorithm to recover logic blocks which become virtually unusable due to shorted pins. Simulation results show that at the up-to-date level of nanodevice defects (108–1011x higher than CMOS), compared to the simple avoidance method, our approach reduces the degradation of resource usage by 87%, improves the routability by 37%, and reduce the degradation of circuit performance by 36%, at a negligible overhead of tool runtime.
In this paper, a combined static and dynamic scheme is proposed to optimize the block placement for endurance and energy-efficiency in a hybrid SRAM and STT-RAM cache. With the proposed scheme, STT-RAM endurance is maximized while performance is maintained. We use the compiler to provide static hints to guide initial data placement, and use the hardware to correct the hints based on the run-time cache behavior. Experimental results show that the combined scheme improves the endurance by 23.9x and 5.9x compared to pure static and pure dynamic optimizations respectively. Furthermore, the system energy can be reduced by 17% compared to pure dynamic optimization through minimizing STT-RAM writes.
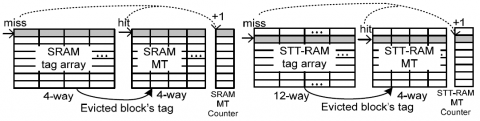
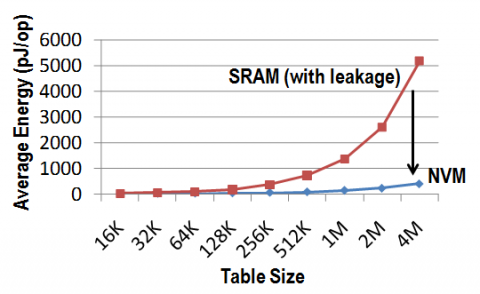
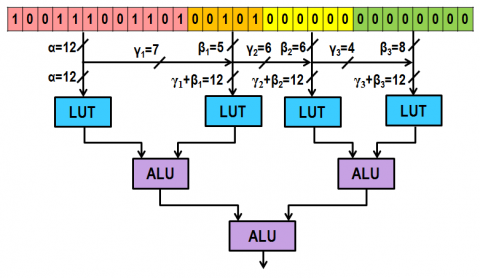
Table lookup based function computation can significantly save energy consumption. However existing table lookup methods are mostly used in ASIC designs for some fixed functions. The goal of this paper is to enable table lookup computation in general-purpose processors, which requires adaptive lookup tables for different applications. We provide a complete design flow to support this requirement. We propose a novel approach to build the reconfigurable lookup tables based on emerging nonvolatile memories (NVMs), which takes full advantages of NVMs over conventional SRAMs and avoids the limitation of NVMs. We provide compiler support to optimize table resource allocation among functions within a program. We also develop a runtime table manager that can learn from history and improve its arbitration of the limited on-chip table resources among programs.
-
Topic: 3-D IC Physical Design and 3-D Architecture Exploration
3-D ICs have recently attracted great interest from researchers and IC designers. Studies demonstrate a potential performance improvement of up to 65% by transferring a placement from 2-D to 3-D and eliminating long interconnects. Furthermore, the multiple device layer structure of 3-D ICs provides a platform to integrate different components, such as digital ICs, analog ICs, memory, RF modules, and different technologies such as SOI, SiGe HBTs, GaAs, etc., into one single circuit stack. Thus, it is a more flexible vehicle for system-on-chip (SoC) and system-in-package (SiP) designs compared to planar 2-D IC technologies.
Although 3-D integration shows promise, significant challenges associated with efficient circuit design and operation have hampered its adoption and further development. The most important issue in 3-D IC is heat dissipation. The thermal problem has already had an impact on the reliability and performance of high-performance 2-D ICs. The problem is aggravated in 3-D ICs, principally for two reasons: the devices are more packed, which results in higher power density; and the insulating dielectric layers between the device layers have much lower thermal conductivities than silicon. Furthermore, the third dimension brings both flexibility and difficulties to physical design algorithms. The existing 2-D metrics cannot be simply extended to generate similar metrics for 3-D designs. Take wirelength as an example: a ``bounding-cube'' might not have enough accuracy for wirelength estimation because of the existence of huge obstacles in z-direction. Also, a 3-D IC physical design problem is usually of higher complexity, with a much enlarged solution space due to the multiple device layer structure. Efficient 3-D physical designs tools, including 3-D floorplanning, placement and routing tools, that are specifically designed to take the thermal problem into consideration, are essential to 3-D IC circuit design.
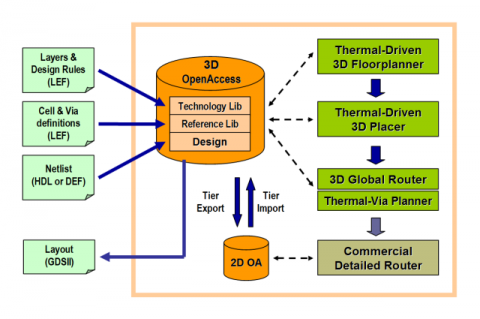
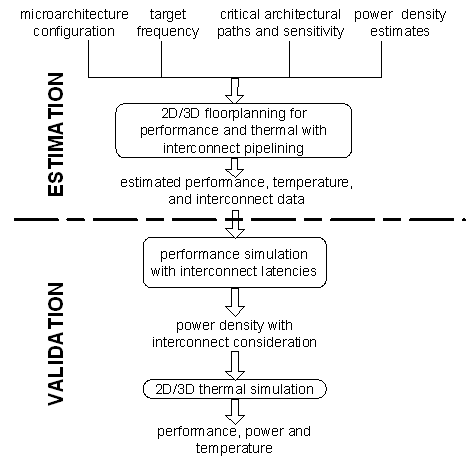
The following figure shows the 3-D physical design tool package that we are working on. Among the three major modules, we have completed the initial version of the floorplanning and routing tools and are working on the placement tool. Our group has also developed MEVA-3D, an automated physical design and architecture performance estimation flow for 3D architectural evaluation which includes 3D floorplanning, routing, interconnect pipelining and automated thermal via insertion, and associated die size, performance, and thermal modeling capabilities.
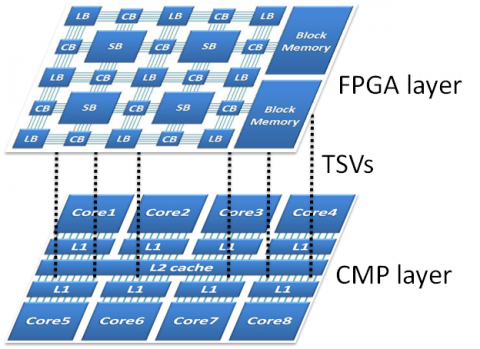
We are also exploring novel 3D architectures. We have proposed the accelerator-over-processor computing platform as shown below. The accelerators in this architecture are designed for a specific domain. They can be shared among applications in the domain. It provides an easy way to extend a general-purpose processor to a domain-specific professor with significant performance improvement and energy savings. We also developed optimization methodologies to maximize the gain under any given area/bandwidth constraints.